平台简介
HBDStreaming 实时流处理平台
实时流处理打破了传统的数据分析和处理的模式,即数据最终积累和落地后再针对海量数据进行拆分处理,然后进行分析统计,传统的模式很难真正达到实时性和速度要求。而实时流处理模型的重点正是既有类似Hadoop中MapReduce和PIG一样的数据处理和调度引擎,由解决了直接通过输入适配接驳到流的入口,流实时达到实时处理,实时进行分组汇聚等增量操作。
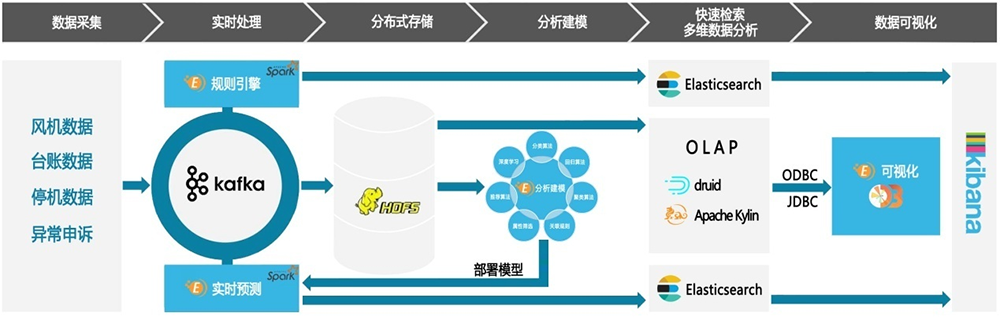
大数据实时流处理平台是基于Apache Spark的Spark Streaming实现的。在大数据平台下,主要负责处理实时数据清洗与基于模型实时预测
从数据的实时采集过程,数据是借助Kafka消息队列以流式进入到大数据平台中,不过刚刚采集的数据,其数据质量是不完全可靠及标准的,那么这时就需要使用实时流的方式对其进行清洗,使其达到相应标准。经过清洗后的数据,就可以进行下一环节完成实时存储了。这个过程,我们可以简单叫做ETL(Extract-Transform-Load)。
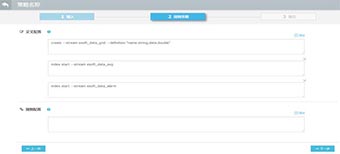
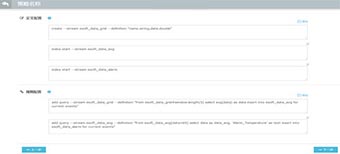
那么数据清洗的过程中,需要配置一些规则。而配置规则的方式可以同系统相应界面操作完成。一般情况下,可以满足常规的所有需求。
通过数据分析平台,根据海量的历史数据,选择相应的算法,选取好最优的参数,构建模型。模型构建好之后,会把模型部署到流平台来完成实时的预测(预警)。
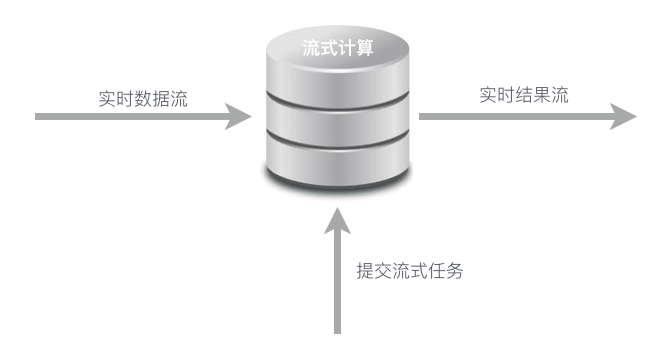
流式计算模型
不同于批量计算模型,流式计算更加强调计算数据流和低时延。
使用实时数据集成工具,将数据实时变化传输到流式数据存储(即消息队列);此时数据的传输变成实时化,将长时间累积大量的数据平摊到每个时间点不停地小批量实时传输,因此数据集成的时延得以保证。
数据计算环节在流式和批量处理模型差距更大,由于数据集成从累积变为实时,不同于批量计算等待数据集成全部就绪后才启动计算任务,流式计算任务是一种常驻计算服务,一旦启动将一直处于等待事件触发的状态,一旦有小批量数据进入流式数据存储,流计算立刻计算并迅速得到结果。
不同于批量计算结果数据需等待数据计算结果完成后,批量将数据传输到在线系统;流式计算任务在每次小批量数据计算后可以立刻将数据写入在线/批量系统,无需等待整体数据的计算结果,可以立刻将数据结果投递到在线系统,进一步做到实时计算结果的实时化展现。
流计算是一种持续、低时延、事件触发的计算任务。