平台简介
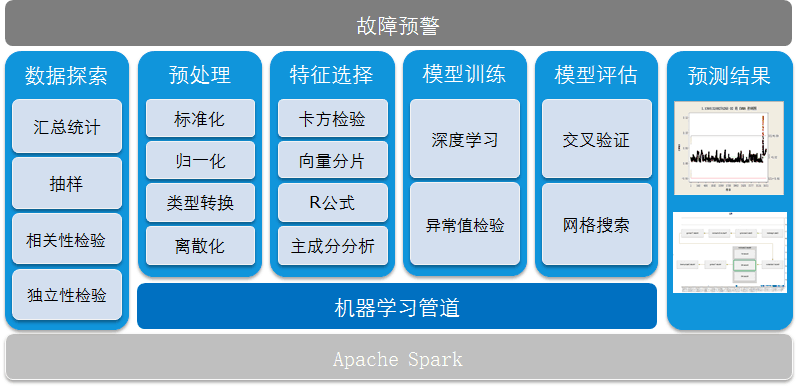
HBDML 机器学习平台
机器学习平台支持用户通过拖拽的方式自定义数据处理流程,实现数据的预处理,同时可以在执行每步流程之后查看当前流程的中间结果数据,用户可以从这些结果中获取大量信息,并将这些结果数据用于模型建立和预测。建立好模型以后,可以选择相应类型的数据进行预测。
大数据平台的架构将数据分层管理,在各层提供数据开放接口,以满足不同数据需求,更有效支撑数据合作运营。同时海量的历史数据能促使合作在第一时间就开展起来。
Spark启用了内存分布数据集,除了能够提供交互式查询外,它还可以优化迭代工作负载。尽管创建Spark是为了支持分布式数据集上的迭代作业,但是实际上它是对Hadoop的补充,可以在Hadoop文件系统中并行运行。
机器学习平台支持集群中原有的规模不足时的系统扩容。Spark和Hadoop平台很容易实现添加新节点到已有集群,操作简单。
大数据在全量数据之上进行数据分析,利用机器学习技术和算法建模,实现对数据的实时分析,能够帮助企业完全勾勒出每个个体客户的DNA,新的Key/Value形式的存储结构摆脱了对维度的限制,可以更加方便的进行数据挖掘分析。